一、原理
冒泡排序的原理很简单, 它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从从Z到A)错误就把他们交换过来。 冒泡排序是一种稳定的排序算法。
冒泡排序不管在什么情况下,时间复杂度都是O(\(n^2\))。
对比插入排序来说,在平均的情况下,插入排序性能是冒泡排序的两倍。
图例:
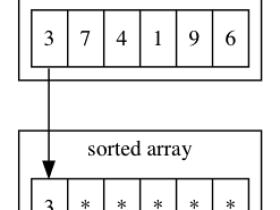
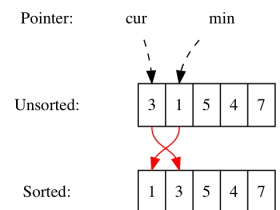
以数组[54, 15, 34, 82, 15, 46, 85, 43]为例:

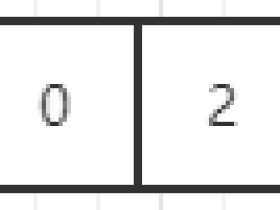
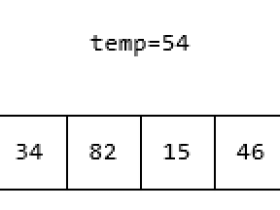
第一次循环先比较54和15,54大于15,交换两个元素:

比较54和34,54大于34,交换两个元素:

比较54和82,54不大于82,不交换:

比较82和15,82大于15,交换两个元素:

按照相同的方式一直对比,直到最后,85被移动到最后:

此时完成一轮冒泡排序,接下来将剩下的元素再次执行同样的操作即可完成对整个数组的排序。
二、代码实现
2.1 C++实现
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
template<typename T> void bubble_sort(vector<T> &data) { int i, j; for (i = 0; i < data.size() - 1; i++) { // 从最后一个元素,对比到当前的data[i]元素 // 因为对比的是j和j - 1,所以循环条件是j - 1 >= i,即j > i for (j = data.size() - 1; j > i; j--) { if (data[j] < data[j - 1]) { swap(data[j - 1], data[j]); } } } } |
2.2 python实现
|
1 2 3 4 5 6 |
def bubble_sort(data): size = len(data) for i in range(0, size - 1): for j in range(size - 1, i, -1): if data[j] < data[j - 1]: data[j - 1], data[j] = data[j], data[j - 1] |
三、冒泡排序的优化
当对第x个数据排序时,冒泡排序每次都会遍历剩下的n-x个元素,即使整个序列已经有序。
因此可以在这一个层面进行优化,如果序列已经有序了,则后面的排序就无需进行了,可以添加一个标记字段来处理这个问题。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
template<typename T> void bubble_sort(vector<T> &data) { int i, j; bool again = true; for (i = 0; i < data.size() - 1 && again; i++) { again = false; // 从最后一个元素,对比到当前的data[i]元素 // 因为对比的是j和j - 1,所以循环条件是j - 1 >= i,即j > i for (j = data.size() - 1; j > i; j--) { if (data[j] < data[j - 1]) { swap(data[j - 1], data[j]); again = true; } } } } |
![[leetcode]199-二叉树的右视图](https://www.dyxmq.cn/wp-content/themes/begin/prune.php?src=https://www.dyxmq.cn/wp-content/uploads/2020/04/f24a8-image.png&w=280&h=210&a=&zc=1)
![【每日打卡】[leetcode]72-编辑距离](https://www.dyxmq.cn/wp-content/themes/begin/prune.php?src=https://www.dyxmq.cn/wp-content/uploads/2020/04/88c60-imageff84a6c5047db6ed.png&w=280&h=210&a=&zc=1)
![【每日打卡】[leetcode]460-LFU缓存](https://www.dyxmq.cn/wp-content/themes/begin/prune.php?src=https://www.dyxmq.cn/wp-content/uploads/2020/04/5b3f2-image.png&w=280&h=210&a=&zc=1)
![[leetcode]125-验证回文串](https://www.dyxmq.cn/wp-content/themes/begin/prune.php?src=https://www.dyxmq.cn/wp-content/uploads/2020/03/5bfa5-image.png&w=280&h=210&a=&zc=1)
![【每日打卡】[程序员面试宝典]17.16-按摩师](https://www.dyxmq.cn/wp-content/themes/begin/prune.php?src=https://www.dyxmq.cn/wp-content/uploads/2020/03/9ecc9-image.png&w=280&h=210&a=&zc=1)
![【每日打卡】[leetcode]876-链表的中间节点](https://www.dyxmq.cn/wp-content/themes/begin/prune.php?src=https://www.dyxmq.cn/wp-content/uploads/2020/03/64d0d-imagece778ab033c9d90d.png&w=280&h=210&a=&zc=1)
![【每日打卡】[剑指offer]面试题40-最小的k个数](https://www.dyxmq.cn/wp-content/themes/begin/prune.php?src=https://www.dyxmq.cn/wp-content/uploads/2020/03/c83c9-imagec745c425c670e18c.png&w=280&h=210&a=&zc=1)
![【每日打卡】[leetcode]-409最长回文子串](https://www.dyxmq.cn/wp-content/themes/begin/prune.php?src=https://www.dyxmq.cn/wp-content/uploads/2020/03/e5589-image788d511d7c1e839c.png&w=280&h=210&a=&zc=1)
![【每日打卡】[leetcode]面试题1.6-字符串压缩](https://www.dyxmq.cn/wp-content/themes/begin/prune.php?src=https://www.dyxmq.cn/wp-content/uploads/2020/03/776bc-image.png&w=280&h=210&a=&zc=1)
评论