一、概述
事务的出现给并发带来了巨大的便利性,它的 ACID 特性使得数据在并发时更加可靠。但是对于事务而言,它也会导致出现第一类丢失更新、第二类丢失更新、脏读、不可重复读以及幻读的问题,当然又出现了多种事务隔离级别来避免在产生这几类问题。那么隔离级别是如何实现的呢?
这就是多版本并发控制 (MVCC)要做的事情了。 《高性能 MySQL 》中对 MVCC 的描述为:
- MySQL 的大多数事务性存储引擎实现的都不是简单的行级锁。基于提升并发性能的考虑,它们一般都同时实现了多版本并发控制。不仅是 MySQL,包括 Oracle 、 PostgreSQL 等其他数据库系统也都实现了 MVCC,但各自的实现机制不尽相同,因为 MVCC 没有一个统一的实现标准。
- 可以认为 MVCC 是行级锁的一个变种,但是它在很多情况下避免了加锁操作,因此开销更低。虽然实现机制有所不同,但大都实现了非阻塞的读操作,写操作也只锁定必要的行。
- MVCC 的实现,是通过保存数据在讴歌时间点的快照来实现的。也就是说,不管需要执行多长时间,每个事务看到的数据都是一致的。根据事务开始时间的不同,每个事务同一张表、同一时刻看到的数据可能是不一样的。
MVCC 的核心功能点是快照,多个事务更新相同数据时,各自都会生成一份对应数据的快照,这个快照被称为一致性读视图 (consistent read view)。有了这个视图之后,每个事务都只对自己内部的视图进行更改,这样就不会影响其他事务了,数据并发就不会受到影响。
问题的关键点就在于快照如何创建以及如何把多个事务的更改统一起来。
因为 MyISAM 不支持事务,因此本篇文章主要讨论的是 InnoDB 。
二、 MVCC 基本原理
首先第一个问题:快照是如何创建的?是不是就是给每个事务都拷贝一份数据呢,是不是有 100G 数据,那每个事务也要拷贝 100G 数据呢?当然不是。
每个事务都有一个事务 ID 叫做 transaction id,这个 id 在事务刚启动的时候向 InnoDB 申请,它不重复并且严格递增。 InnoDB 隐藏了一个包含最新改动的事务 id,每个事务修改后都会把这个字段设置为自己的事务 ID 。其他事务启动的时候记录下这个最新 ID,然后修改的时候比对 ID 是否有修改。如果没有修改,说明这一行没有改动过,当前事务也能直接修改。如果 ID 变化了,则就要查找 undolog,找到可用的合适的记录。
因此,创建快照就只要记录下这个事务 ID 就可以了,无需复制所有的数据。
在实现上,InnoDB 给每个数据表都添加了隐藏的三列数据 DB_TRX_ID/DB_ROLL_PTR/DB_ROW_ID,三者的含义:
DB_TRX_ID: 标记了最新更新这条行记录的 transaction id,每处理一个事务,其值自动+1 。DB_ROLL_PTR: 回滚指针,记录了最新一次修改该条记录的 undo log,回滚的时候就通过这个指针找到 undo log 回滚。DB_ROW_ID: 当数据表没有指定主键时,数据库会自动以这个列来作为主键,生成聚集索引。
每次事务更新数据的时候,都会生成一个新的数据版本,并且把 transaction id 赋值给这个数据版本的事务 ID(即 DB_TRX_ID 列) 。同时,旧的数据版本要保留 (通过 undo log 保留),并且在新的数据版本中,能够有信息可以直接拿到它。也就是说,数据表中的一行数据,其实可能有多个版本。
例如存在以下数据表:
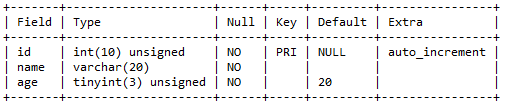
它实际上的表现形式为:

假设此时修改年龄为 25,此时数据列和 undo log 的状态是:
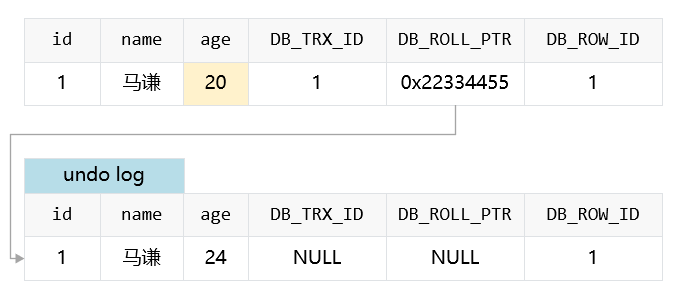
undolog 新生成了一个记录,保存了改动之前的数据。新记录中,通过设置 DB_ROLL_PRT 指向备份的 undo log 记录,方便回滚。如若再次修改年龄为 18,那么两者的状态为:
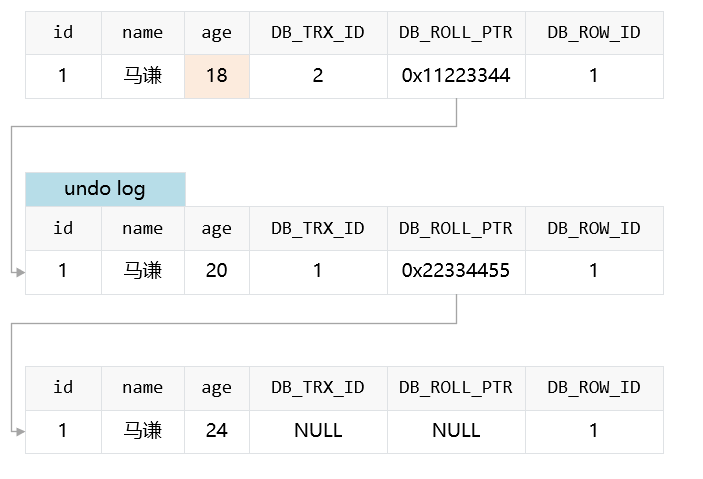
三、 MVCC 具体过程
以下通过一个示例来描述 MVCC 具体的执行过程:
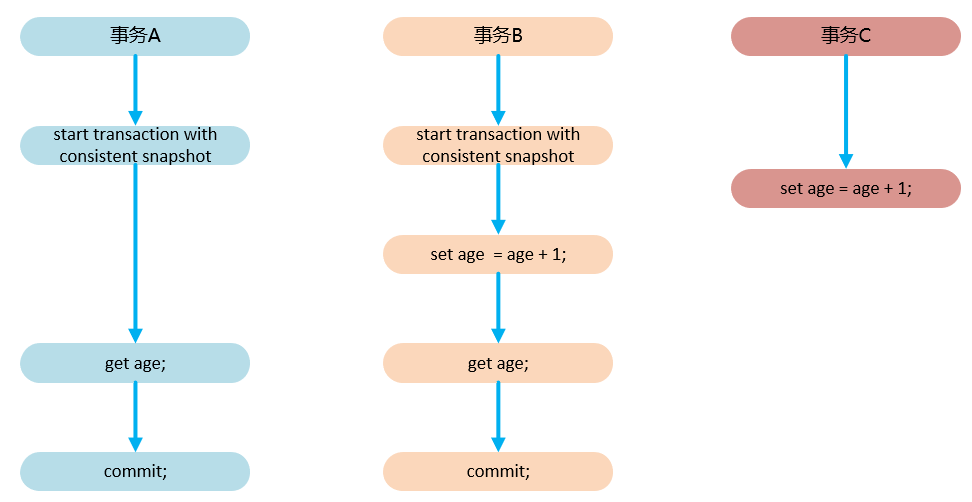
关于 start transaction with consistent snapshot:
前面我们说过,行锁的加锁实际并不是事务启动的时候就创建的,而是在修改对应行的时候才创建的。这里的一致性视图默认情况下和视图也是一样,用到的时候才创建,并非事务已启动就创建。
start transaction with consistent snapshot 语句的作用就是在启动事务的时候就创建一致性视图。
以上面的学生表为例,同时存在三个事务修改同一行数据中的值,其中事务 A 和事务 B 先执行,然后事务 C 更新数据并提交。此刻事务 A 和事务 B 的更新和查询记录的结果会是怎样?
初始时的行数据为:
| id | name | age |
|---|---|---|
| 1 | maqian | 24 |
测试
首先启动启动两个终端模拟事务 A 和事务 B,执行 start transaction with consistent snapshot 。
然后开启第三个终端模拟事务 C,执行:
|
1 2 3 |
mysql> update stu_info set age = age + 1 where name = 'maqian'; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 |
然后在事务 B 执行以下操作:先查询 age 的值,然后也把 age 加一,然后再查询 age 的值。
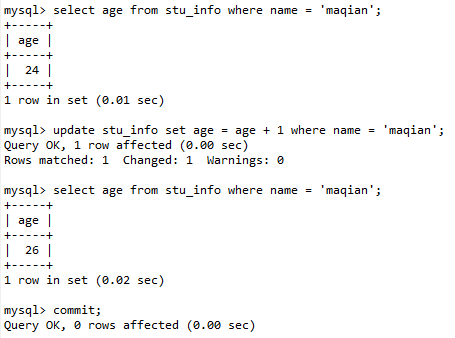
事务 B 在更新操作执行之前,查询 age 的值是 24,执行更新操作之后,再查询 age 值是 26 。
此时事务 A 查询 age 的值是 24:
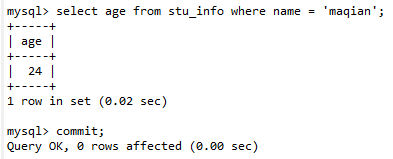
因此能得到的结论是:
- 事务 B 在更新数据前查到的 age = 24,更新后查到的 age = 25 。
- 事务 A 查询到的数据是 24 。
看起来不符合逻辑,为什么会这样呢?
3.1 查询逻辑
我们以 trx_id_first/trx_id_last/trx_id_currennt 分别表示事务的低水位、高水位和当前事务。
如何理解高低水位:
- 低水位:已经提交事务的最大值,即启动当前事务时候已经提交了的事务。
- 高水位:未开始事务的最小值,即当前事务启动时还未启动的事务。
- 当前事务:高低水位之间的事务,即当前事务启动时候已经存在的未提交事务。
以图形表示为:
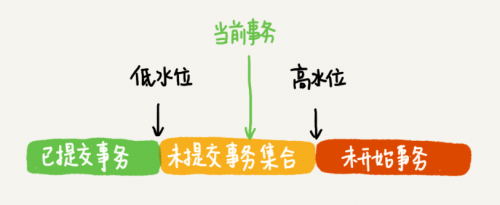
图片来源:极客时间
在事务开始的时候,除了生成一致性视图,还要生成一个对应的视图数组,这个数组里面表示的就是所有未提交事务的集合 (黄色区域) 。查询数据的时候有三种情况:
- 数据未提交,数据不可见。
- 数据已提交,但是事务 ID 处于当前事务的高水位段,不可见。
- 数据已提交,并且事务 ID 实在当前事务之前创建,可见。
以上面的测试过程为例,事务 A 的 id 等于 1,事务 B 的 id 等于 2,事务 C 的 id 等于 3 。那么事务启动时,事务 A 的视图数组为 [0, 1],事务 B 的视图数组为 [0, 1, 2],事务 C 的视图数组为 [0, 1, 2, 3]:
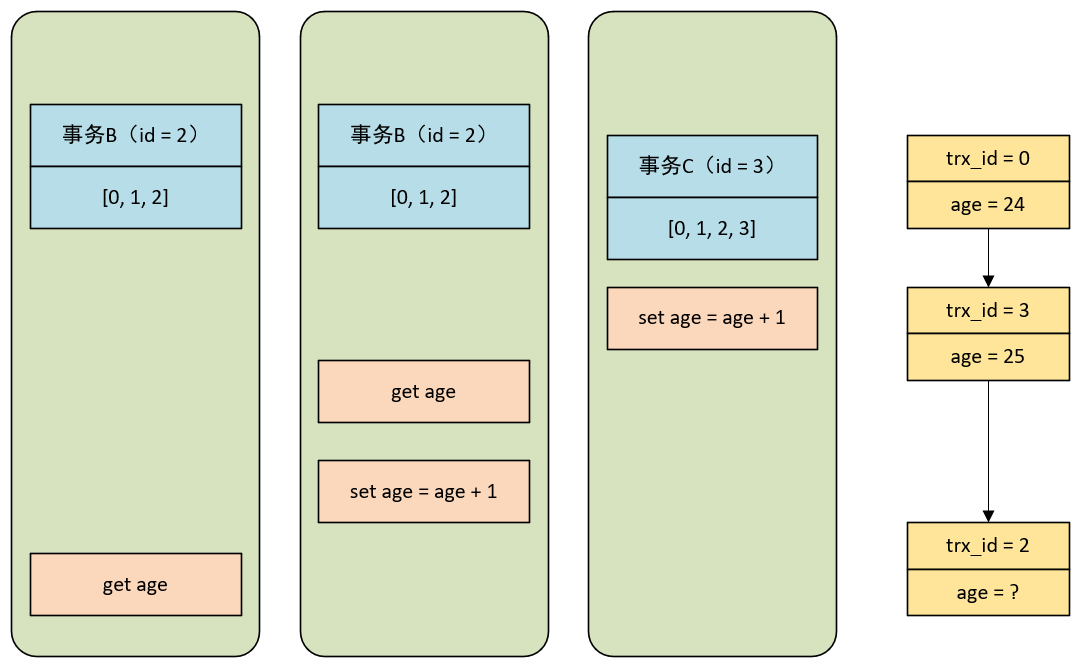
事务 C 最后启动,因为是自动提交,因此执行完 update 之后就已经 commit 了,此时记录的 DB_TRX_ID = 3 。它处于事务 B 的高水位区,虽然已经提交但是也不可见,命中第二条规则。因此它要先通过 undo log 找到一个可见的版本,找到上一个版本 trx_id = 0 位于它的可见区,然后读取这条记录的 age 值为 24.
而事务 B 对于事务 A 而言,也是处于高水位区,并且事务 B 修改 age 之后没有提交,所以 rtx_id = 2 的事务对事务 A 是不可见的,命中了规则一,要往前找其他版本。先找到上一个版本 trx_id = 3 后发现还不是可见的,需要继续往前找,找到 rtx_id = 0 的记录,它对事务 A 可见,再读取 age 值为 24 。
3.2 更新逻辑
上面有一个不合逻辑的点在于事务 B,事务 B 它在更新 age 的前后分别查询 age 的值是对不上的:加一之前是 24,加一之后是 26 。这是个什么逻辑呢?
对于更新而言,它有一个很重要的概念是当前读,当前读的意思是:更新的时候,要使用当前版本的记录来读。所谓当前版本指的就是最新更新后的记录,在上面的例子中也就是 trx_id = 3 的记录。
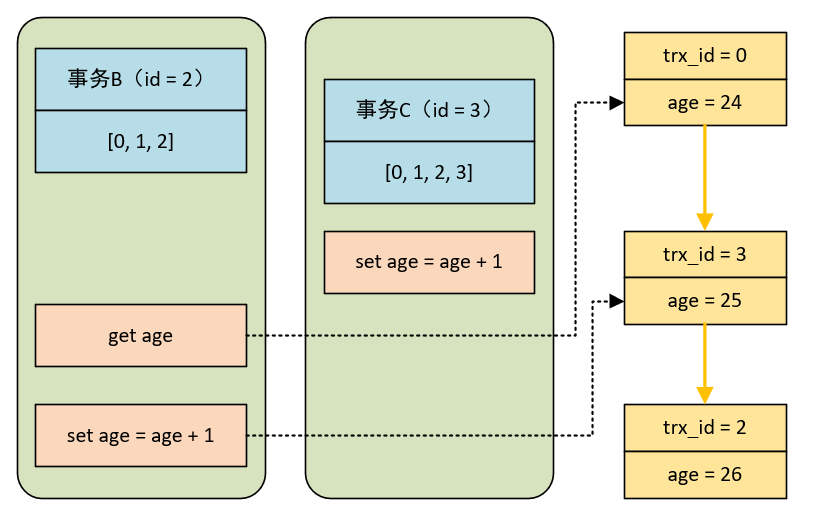
在事务 B 修改 age 的值之前,此时读取 age 值就像上面所说:先找到 trx_id = 3 的记录,发现不可见,然后再读取 trx_id = 0 的记录。
但是事务 B 在修改 age 的时候,先读取当前是最新的改动 trx_id = 3 这条记录,此时 age 的值为 25 。然后事务 C 把 age 值加一,并设置 trx_id = 2 。事务 C 再读取数据,发现最新的改动事务 id 是 2,也就是自己。处于未提交的当前事务区,就能读到 age 是 26 了。