一、 RTT 和 RTO 的概念
TCP 作为一个面向连接的、可靠的传输协议,内部实现了一个重传计时器来保证数据能传输到对方。每发送一个数据包,就给这个数据设置一个重传计时器。如果在计时器超时之前收到了针对这个数据包的 ack,就取消这个计时器。如果没有收到,则开始发起重传。计时器超时的时间被称为 RTO,这个时间的确定取决于 RTT 。
关于两者详细的解释:
RTT(Round Trip Time):一个连接的往返时间,即数据发送时刻到接收到确认的时刻的差值;RTO(Retransmission Time Out):重传超时时间,即从数据发送时刻算起,超过这个时间便执行重传。
关于 RTT 和 RTO 值的确定一直以来都是值得讨论的地方,如何让 RTO 能适应网络变化。
二、 RTT 的测量
每发送一个分组,TCP 都会进行 RTT 采样,这个采样并不会每一个数据包都采样,同一时刻发送的数据包中,只会针对一个数据包采样,这个采样数据被记为 sampleRTT,用它来代表所有的 RTT 。
采样的方法一般有两种:
- TCP Timestamp 选项:在 TCP 选项中添加时间戳选项,发送数据包的时候记录下时间,收到数据包的时候计算当前时间和时间戳的差值就能得到 RTT 。这个方法简单并且准确,但是需要发送段和接收端都支持这个选项。
- 重传队列中数据包的 TCP 控制块:每个数据包第一次发送出去后都会放到重传队列中,数据包中的 TCP 控制块包含着一个变量,tcp_skb_cb->when,记录了该数据包的第一次发送时间。如果没有时间戳选项,那么 RTT 就等于当前时间和 when 的差值。
linux 内核中,更新 rtt 的函数为 tcp_ack_update_rtt:

三、 RTO 的计算
3.1 经典方法
为了避免单次 RTT 波动,计算 RTO 时新引入了变量 SRTT,表示更加平滑的 RTT 数值,它的计算方法:
|
1 |
SRTT = x(SRTT) + (1 - x)RTT; |
x 被称为平滑因子,一般建议设置在 [0.8, 0.9],意思是 SRTT 值百分之八十来自于之前的值,百分之二十来自于当前值。然后计算 RTO 的方法为:
|
1 |
RTO = min(ubound, max(lbound, y(SRTT))); |
y 是时延离散因子,推荐值为 [1.3, 2.0],ubound 是 RTO 的上边界,lbound 是 RTO 的下边界。
算法的缺点
在 RTT 波动较大时,RTO 不能明显适应网络变化。
3.2 标准方法
标准方法引入了平均偏差的概念,它类似于统计学里面的方差,但是因为方差的计算过程代价较大,对于快速 TCP 来说不太适合。假设 rtt 的值为 M,RTO 的计算方式为:
|
1 2 3 |
srtt = (1 - g)srtt + g(M); rttval = (1 - h)rttval + h(|M - rttval|); RTO = srtt + 4(rttval); |
其中 g 设置为 1/8,h 设置为 1/4,对 srtt 而言,它有 1/8 取决于当前值,7/8 取决于现有值。当 RTT 变化时,偏差增量越大,RTO 的增量也越大。
关于计算 RTT 和 RTO 的算法,还有很多种,历史上针对这个的探讨从未停止过。
比较出名的拥塞算法还有谷歌的 bbr 算法,高版本的 linux 内核已经合入了 bbr 算法作为拥塞控制算法。
四、其他
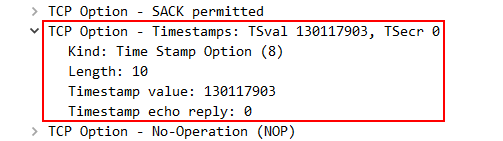
4.1 TCP Timestamps 选项
时间戳选项的作用是为了方便计算 RTT,每发出一个数据包,就记录下发送时间,收到数据包时就能准确的获知到数据包往返时间了。
通过 TCPDUMP 抓包很容易就能看到 Timestamps 选项: