一、梳排序简介
梳排序是冒泡排序的一种优化方案,主要是为了解决冒泡排序中的尾部小数值问题。它主要的思想是通过比较元素和固定步长位置上的数据,先进行部分优化,然后逐步减少步长,以此来对数据进行预处理。
以数组 [3,1 5, 2, 4] 为例,假设步长是 2,那么就分别处理 [3, 5, 4] 和 [1, 2],先局部优化。优化完成后,再使用冒泡排序。
关于步长的选取
步长并不是逐步递减的,步长的选取一般通过一个步长因子来控制:
- 初始化时,步长等于数组长度除以步长因子。
- 后续的所有步长都等于前一次步长除以步长因子,直到步长小于等于 1 。
从实验结果来看,这个步长因子设置为 1.3 时能获得较好的性能,并且实验数据证明,梳排序的良好性能甚至可以与快速排序媲美。
排序示例
以数组 [41, 11, 18, 7, 16, 25, 4, 23, 32, 31, 22, 9, 1, 22, 3, 7, 31, 6, 10]为例,它的长度是 19,计算得到的步长分别是 [14, 10, 7, 5, 3, 2],它的预处理过程可以整理为:
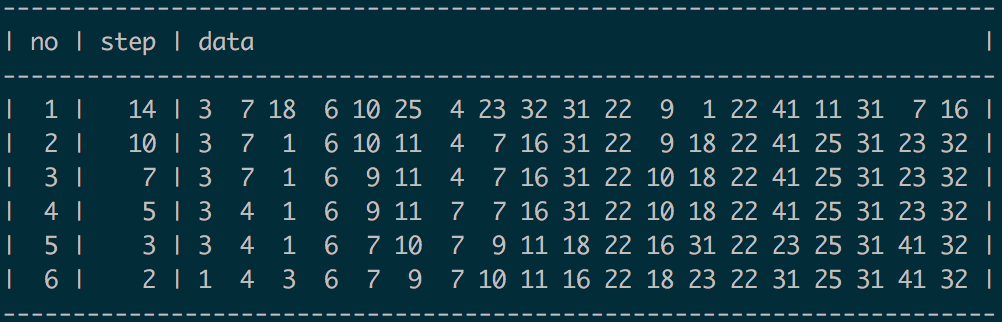
其中 no 表示第几趟排序,step 表示步长,data 是当前经过处理后的数组。很明显可以看出经过 6 次预处理后,数据已经基本有序了。
此时再通过冒泡排序来对整体排序就能减少很多工作量了 (实际上只需要再做一次冒泡排序就能完成排序了) 。如果没有第一阶段的处理,冒泡需要 19 趟排序才能完成,而经过处理后,第 8 趟排序就已经有序了。此时排序结束,节省了一半以上的时间。
二、代码
C++代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
const float factor = 1.3; template<typename T> void comb_sort(T data[], const unsigned int n) { unsigned int i, j, step = n; bool flag = true; if (n < 2) return; // 步长处理 while ((step = (unsigned int) (step / factor)) > 1) { for (i = n - 1; i >= step; i--) { j = i - step; if (data[i] < data[j]) my_swap(data[i], data[j]); } } // 冒泡排序 for (i = 0; flag && i < n - 1; i++) { flag = false; for (j = 1; j < n - i; j++) { if (data[j] < data[j - 1]) { my_swap(data[j], data[j - 1]); flag = true; } } } } |